Cosplaying as Morusque, Stray's Guitar Robot - Part 2: Guitar Software
October 31, 2023

To enable the guitar to play music from the game, an SBC needs to run a script capable of playing audio on command. This can be understood through the following diagram:
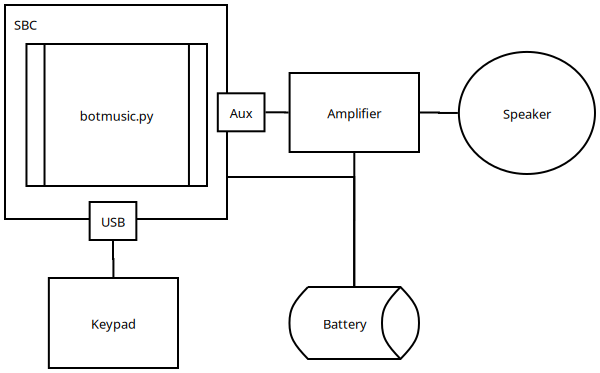
During Anime Expo 2023, many people questioned why I chose an SBC over an Arduino. Frankly, I found the SBC easier to work with and didn't want to fuss with an Arduino. The only downside is the startup time, but it's a non-issue if you power it on once and leave it. Given the setup's low power consumption, longevity isn't a concern.
The Distro
The SBC should boot into a headless Linux instance and automatically run a script. This script listens for a keypress and plays the associated media file. Any headless Linux distro will suffice; for this tutorial, I recommend flashing the SBC's SD card with a Debian-based distro such as Raspbian or Ubuntu.
For my own implementation, I used Ubuntu Server. You can find the images here: - Raspberry Pi - Libre Computer
Music Script
The script waits for the user to press a number key between 1 and 9 and then plays the song mapped to that key. If any other key or the escape key is pressed, the music stops.
Once you have flashed an OS onto the SD drive, create the following file ~/botmusic.py:
from os.path import join
from pygame import mixer
from pynput import keyboard
SONGS = {
1: "1_petite_valse.mp3",
2: "2_ballad_of_the_lonely_robot.mp3",
3: "3_untitled.mp3",
4: "4_the_way_you_compute_tonight.mp3",
5: "5_tomorrows.mp3",
6: "6_cooldown.mp3",
7: "7_mildly_important_information.mp3",
8: "8_unreadable.mp3"
}
def play_song(number):
file = join('assets', SONGS[number])
mixer.init()
mixer.music.load(file)
mixer.music.play(-1)
def stop_song():
try:
mixer.music.stop()
except:
pass
def on_press(key):
try:
if key.vk == 65437:
number = 5
else:
number = int(key.char)
stop_song()
play_song(number)
except:
pass
def on_release(key):
if key == keyboard.Key.esc:
stop_song()
return False
listener = keyboard.Listener(
on_press=on_press,
on_release=on_release)
listener.start()
listener.join()
I'm not sure if the if key.vk == 65437 segment is strictly necessary. During testing, I encountered an issue where the 5 key wasn't being detected for reasons I couldn't be bothered to test, and this was a workaround. It's worth testing it on your own to see if it affects your specific implementation.
Music Assets
Create a folder to hold the music assets:
mkdir assets
The SONGS variable points to several mp3 files that are not included in this tutorial due to copyright restrictions. You will need to find or extract these songs on your own and place them in the assets folder. I recommend extracting the songs from either YouTube or SoundCloud using youtube-dl.
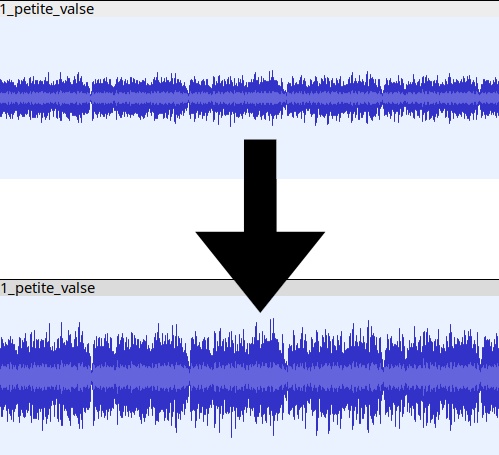
Once you have retrieved the sound assets, amplify them in Audacity. To do this, go to Effect -> Volume and Compression -> Amplify. Audacity will automatically determine the optimal Amplification (db) setting for your selection, so you don't need to adjust the slider. This will normalize the audio and make it more audible.
Preparing the Script's Environment
Set up the virtual environment with the following commands:
sudo apt install virtualenv
virtualenv -p `which python3` .botenv
source .botenv/bin/activate
pip install pygame pynput
Create the following file ~/botmusic:
source ~/.botenv/bin/activate && python ~/botmusic.py
Make it executable:
chmod +x ~/botmusic
Autostart
Next, you need to ensure that the script automatically runs when the device is powered on.
To start, Linux needs to automatically log into the user that will execute the script. Run the following command:
sudo systemctl edit getty@tty1.service
After a text editor opens, replace everything with the following contents while setting the appropriate username:
[Service]
ExecStart=
ExecStart=-/sbin/agetty --noissue --autologin <USERNAME> %I $TERM
Type=idle
Since the script will require root access as it listens for keyboard inputs without X11, run the following command:
visudo
Add the following line so that root can execute the script:
%sudo ALL=(ALL:ALL) /home/<USERNAME>/botmusic
OPTIONAL: If you are concerned about security, you can run the following commands. This step is not strictly necessary:
chmod 111 ~/botmusic
sudo chown -R root:root botmusic
Finally, edit ~/.profile and add the following line:
sudo ~/botmusic
Conclusion
That's essentially it. I recommend booting up and testing the auto-start script multiple times before using the guitar in a production setting. To improve boot time, consider disabling unnecessary services like networking.
Cosplaying as Morusque, Stray's Guitar Robot - Part 1: The Face
October 31, 2023

Overview
Morusque is one of the first characters players encounter in the video game Stray. He plays the random music sheets found throughout the game's first area. I was instantly captivated by this character and decided to cosplay him.
This article is the first in a series detailing how I created a Morusque costume. We'll start by discussing the basic mechanics that control the face.

Design
Overall, the design mimics a standard desktop computer, with the exception of the AR glasses and camera, which provide vision through the mask. In retrospect, a periscope would have been a more cost-effective and efficient option; this appears to be the standard for most other costumes that obstruct vision.
The keypad enables the user to select which facial expression will appear on the LCD panel at any given time. Initially intended solely as a faithful representation of the character, it later evolved into a means of interacting with people.
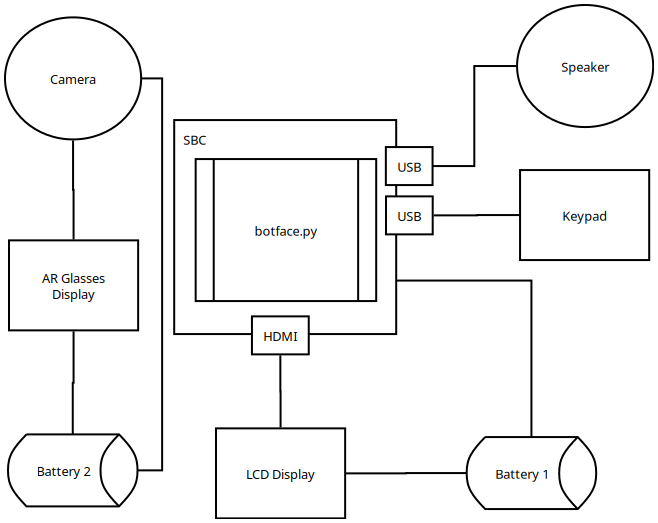
The Distro
The SBC should boot into a Linux instance and automatically run the botface script. An X11 instance is required.
For my implementation, I used Lubuntu, a lightweight desktop environment that employs LXQt. Finding a suitable Lubuntu image for your SBC might be challenging. However, it's relatively straightforward to download an Ubuntu server or desktop image and install the Lubuntu desktop environment on it. You can find images here: - Raspberry Pi - Libre Computer
Face script
Code for the face script is available here. After downloading, execute the following commands
sudo apt install virtualenv
virtualenv -p `which python3` .faceenv
source .faceenv/bin/activate
pip install pygame
The face relies solely on Pygame for all rendering logic. Keys 0-9 control which face is displayed. Some faces may appear briefly, while others remain on screen until changed.
To create your own face, define a class in botface.faces with a render method and register it in main.py. A simple example can be found in botface.faces.yes; for more complex animations, refer to botface.faces.talking.
Autostart
Once powered on, the SBC should automatically run the botface script. LXQt offers a straightforward method for autostarting applications through the LXQt Configuration Center.
To avoid the login prompt from blocking autostart, edit /etc/sddm.conf:
[Autologin]
User=<USERNAME HERE>
Session=lxqt.desktop
Relogin=true
Conclusion
Overall, the setup is straightforward. You can build everything using off-the-shelf hardware and software. In a separate article, I'll discuss crafting the physical components that house the hardware and contribute to the aesthetics of the face.
The end goal should resemble the following:
Moving workspaces between outputs in i3
May 29, 2023
A feature sorely missing from i3 is the ability to switch workspaces between displays. In i3, workspaces are tied to a single display, while in window managers like xmonad, workspaces can freely move between displays. Having recently migrated to i3 from xmonad, this was a feature I sorely needed. Fortunately, this behavior can be implemented with a small hack.
Before beginning, make sure the following packages are installed:
xrandr
xdotool
Put the following script somewhere and make it executable. This only works on horizontally stacked displays, and there's a small delay when moving between workspaces:
#!/bin/bash
workspace="$1"
displayinfo="$(xrandr --listmonitors | cut -d' ' -f4,6 | grep -v '^$')"
displays="$(echo "$displayinfo" | awk '{print $2}')"
maximums="$(echo "$displayinfo" | awk -F '/' '{sum += $1; print sum}')"
X="$(xdotool getmouselocation --shell | awk -F '=' '/X=/{ print $2 }')"
i3_output=$(i3-msg -t get_workspaces)
readarray -t d_arr <<< "$displays"
readarray -t m_arr <<< "$maximums"
for index in "${!d_arr[@]}"; do
concatenated="${d_arr[index]} ${m_arr[index]}"
maximum=${m_arr[index]}
if [ "$X" -le "$maximum" ]; then
workspaces=$(echo "$i3_output" | jq -r --arg output "${d_arr[index]}" '.[] | select(.output == $output) | .name')
readarray -t workspace_array <<< "$workspaces"
for workspace in "${workspace_array[@]}"; do
if [ "$workspace" -eq "$w"]; then
i3-msg workspace number $1
exit
fi
done
i3-msg "[workspace=\"$1\"]" move workspace to output ${d_arr[index]}
i3-msg workspace number $1
exit
fi
done
Then add the following lines to ~/.config/i3/config. This assumes there are workspaces 1-10 and may vary depending on your individual configuration:
set $ws1 "1"
set $ws2 "2"
set $ws3 "3"
set $ws4 "4"
set $ws5 "5"
set $ws6 "6"
set $ws7 "7"
set $ws8 "8"
set $ws9 "9"
set $ws10 "10"
bindsym $mod+1 exec <path to script> $ws1
bindsym $mod+2 exec <path to script> $ws2
bindsym $mod+3 exec <path to script> $ws3
bindsym $mod+4 exec <path to script> $ws4
bindsym $mod+5 exec <path to script> $ws5
bindsym $mod+6 exec <path to script> $ws6
bindsym $mod+7 exec <path to script> $ws7
bindsym $mod+8 exec <path to script> $ws8
bindsym $mod+9 exec <path to script> $ws9
bindsym $mod+0 exec <path to script> $ws10
Notes on crawling the web
May 18, 2021
Introduction
Web crawlers are a very common, yet often misunderstood, category of software solutions. Here is a list of common problems/solutions/gotchas/etc I've encountered over the years. Hopefully it aids others interested in the problem space.
Primitives
Resource Fetcher
- Downloads resources from the web.
- Resources are generally webpages identified by a URI.
- Sends resources to the Resource Extractor.
Resource Extractor
- Extracts URIs from downloaded content.
- This is typically where out-of-the-loop business logic for analysis starts.
- Sends URIs to the Frontier Strategy.
Frontier Strategy
- Determines what URIs should be downloaded next.
- Filters out duplicate and unwanted URIs.
- Sends prioritized URIs to the Resource Fetcher.
Fig 1. The core loop of web crawler primitives.
Filtering URIs
Duplicate detection
Duplicated links and pages already visited by the web crawler need to be filtered out before being passed to a fetcher. A bloom filter, hash table, or combination of both can be used in this instance.
Bloom filters are not perfect, lookups can return false positives. However, the error rate for false positives can be tracked and adjusted as the structure fills up. If the filtering constraints allow for a margin of error, then a bloom filter can be used in isolation, otherwise it must be used in combination with a hash table.
Hash tables allow for quick lookups without false positives. However, storage and sharding constraints often become a major problem as the index grows in scale. If the hash table is persistent, then IO constraints become another factor. A hash table can be used in isolation if these factors are taken into consideration.
Resource Extraction
The encoding and format of online content varies considerably, formatting standards are more like guidelines than actual rules. It's important to take these factors into consideration. A finite-state machine based parser is an ideal extraction solution, as it can handle multiple formats and ignore conventions.
Content storage
Fetched content will need to be accessed by various stages in the pipeline. For single-node instances, the filesystem is more than sufficient. It's important to have a mechanism that expires
- Amazon S3 is a great cloud solution.
- Swift is a solid open source solution.
- stream-store is a tool I wrote that meets the bare-minimum requirements for small scale crawl storage.
Zero-copy
Employing some form of zero-copy when fetching resources will substantially reduce CPU usage and makes single-node crawling significantly more tenable. However, most HTTP libraries will not support this out of the box, you may have to write one on your own.
Resource prioritization
Crawling a single website or limited number of domains
Typically, resource prioritization is not required when crawling single or limited set of websites. Either specialized business logic is used to filter URIs or the entire set is enumerated.
PageRank
PageRank is a very solid ranking algorithm and offers an excellent starting point when building a web crawler. It's not uncommon for solutions such as Neo4j to offer production-ready implementations. Nearly every major programming language has a third-party PageRank library available.
Vertex counting (in-degree/out-degree)
Prioritizing based on edge count works relatively well on smaller domain sets. In-degree serves as a weak proxy for ranking pages that might be useful for analysis. Out-degree is often an excellent indicator for ranking pages that can expand the graph. However, vertex and unique domain counts are often exploited by adversarial pages trying to improve search ranking (see the Adversarial environment section for more).
Community detection
When prioritizing resources based on community structure, a clustering method is necessary. My experience with this is limited, but the following algorithms have been useful when performing community detection:
Expressing priority
Ranking algorithm output must be compatible with consumer priority. Different stages in the core loop usually communicate using some form of a message queue. Message brokers like RabbitMQ support consumer priority out-of-the box. Others, like Kafka, require setting up separate queues.
Adversarial environment
It's not uncommon to run into websites that will break your web crawler. This can sometimes be intentional and/or malicious, but not always.
Rate limiting
Some websites may, understandably, seek to rate limit requests. To manage this situation, the fetcher will need to track error rates over time and defer fetching URIs for later.
XSS
Be extremely careful when rendering crawled content in a web browser. It is not uncommon to find websites that include malicious XSS attacks.
Crawler traps and depth limits
Some websites may either be too large, or employ strategies to keep your crawler hyper focused on their content.
Mitigation:
- Set per-website depth limits or maximum page counts.
- Do not count subdomains separately.
- If community detection is employed, then consider community-level maximums.
- Block websites that lead your crawler to a large number of erroneous requests.
Standards don't exist
Responses may not always follow convention. An HTTP header could be malformed, the indicated Content-Length may be incorrect, or the server feeds you random bytes for as long as possible.
Mitigation:
- Set a maximum byte size for the HTTP header and content read buffers.
- Set timeouts for header/content reads/writes.
- Assume unstructured formats, use finite-state machines to parse out relevant content.
robots.txt
DO NOT ignore the robots.txt file. This is the shortest path to getting blacklisted or having your infrastructure shut down. Your user agent will be tracked and published by third parties, so play nice.
Some robots.txt files will include a honeypot within Disallow links. Visiting these URIs may intentionally waste resources or ban your crawler's IP address. Play nice and don't visit Disallow links.
Website admins will complain
Administrators will notice high request volume. Having contact information readily available for them will prevent any complaints going into your cloud provider's inbox.
Mitigation:
- Set your user agent as a disposable email.
- Expose a web server on the fetcher's IP addresses containing information about the web crawler. This is recommended practice for tor exit nodes.
But I want to crawl the WHOLE web
This problem deserves an article of its own, I may write about how to do this in the future.
Summary of Crawling tor
December 08, 2018

Synopsis
The first iteration of the Esper crawler ran successfully for about a week on a single laptop computer. The frontier and seed strategy proved to be useful to gain a high-level perspective. However, only surface-level information was discovered. Due to the requests per-second limitation, only a limited number of pages could be crawled.
Esper
Esper is the 4th generation of my web crawling technology, the current iteration (6th gen) is known as Bandit.
Seed strategy
Extract all .onion domains from the first Google search result page for the query “Hidden Service List”.
Frontier strategy
- [Priority 0] Enumerate through the list of all unique unvisited domains.
- [Priority 1] Enumerate through the list of all unvisited URLs for websites that have a high in-degree value on the hidden service directed graph.
- [Priority 2] Enumerate through the list of all unvisited URLs.
Stats
General
- Initial seed: 352 websites
- Total pages detected 1,233,575
- Total node count: 25,056
- Total Edge count: 100,876
- Total active nodes: 7,323
- Total active edges: 83,14
- Total pages crawled: 28,553
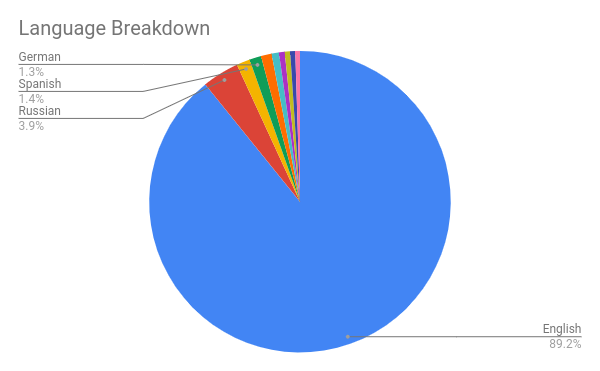
Language
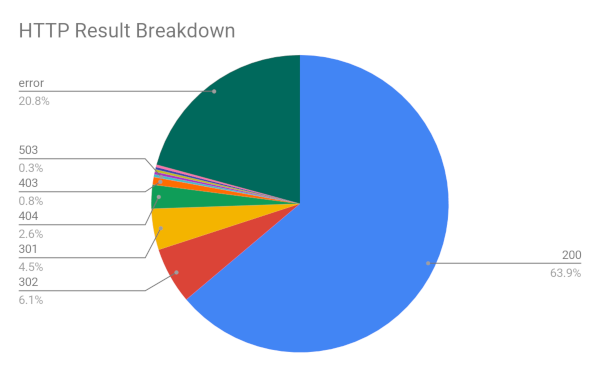
HTTP Responses
Shortcomings/Improvements
-
The fetcher component of the crawler runs at a rate of approximately 1 request/second. This significantly limits the ability to exhaust the entire hidden service directory and URL listing. Significant improvements to the fetcher component must be made in order to adequately gain a more complete picture of the darknet.
-
A target speed of 10 RPS should be achievable with a single network card and CPU.
-
A target speed of 100 RPS should be achievable if cloud services are leveraged.
-
If an adequate picture cannot be extracted with 10 RPS and an appropriate frontier strategy, then Esper will need to be migrated to the cloud.
-
-
A larger seed from more diverse sources should be used to increase the graph size. It is possible that there were self-contained networks that were not found.
- The seed was biased towards English, which may be why the majority of pages crawled were in English.
-
Consider a graph database.
- The domain graph is small enough to run analytics on a single machine.
- If more graph-based analytics continue to be generated, then a graph database would offer significant performance advantages.
-
The frontier strategy has limitations.
- More priority should be given to domains that surfaced from graph-based analytics.
- Deprioritize or blacklist domains with large out-degrees where outbound connections link to nothing.
-
Prioritize large out-degrees that are well connected.
- A number of index sites were not fully enumerated due to frontier limitations. These pages should be prioritized.
-
Deprioritize or blacklist domains with a disproportionate amounts of errors and low in-degree on connected nodes.
- There is no blacklisting mechanism
- Search forms and query strings should be brute-forced if a pattern is easily recognized.
- Deprioritize or blacklist domains within a large localized cluster
- There is no detection of adversarial websites.
- Error count from out-degree should be weighted.
-
The link extractor has limitations.
- Add the illume finite state machine to the link extractor.
-
Graph Visualizations should be built to include the following features
- Language
- Term frequency
Anomalies
Enumeration of .onion hash space
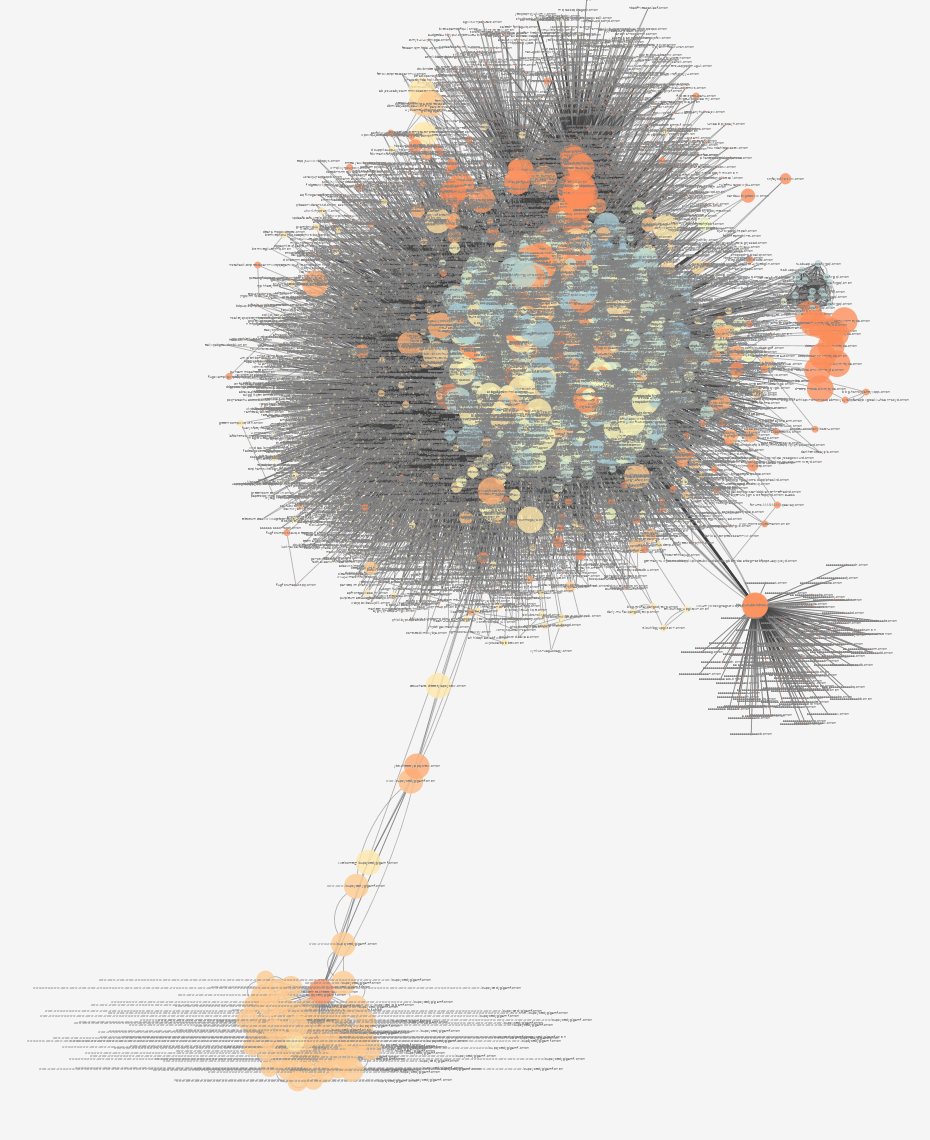
The crawler found a website that enumerated every single domain. Fortunately, the frontier did not prioritize this website, as there were a large number of domains that remained uncrawled. This page was of particular interest, due to the existence of a mirror. This mirror guaranteed that the enumerated websites would have an in-degree of >= 2, which may fool some graph-based frontier strategies.
Anomaly visualized within directed graph
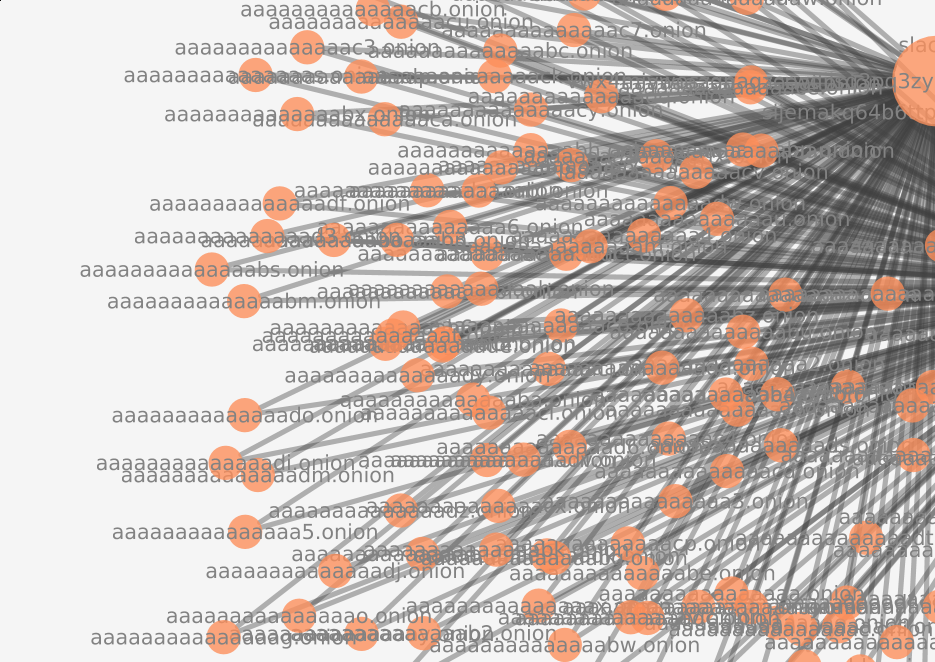
Request by hidden service owner to feed website to web crawlers

Better view of the anomaly within directed graph
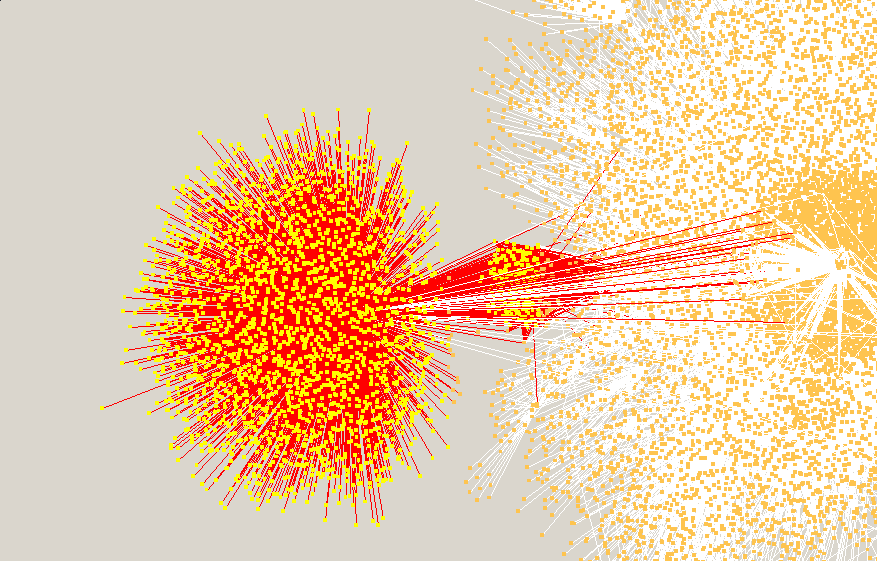
Unconnected segments in the directed graph
Small unconnected network found during initial visualization attempts. The other two nodes to the right later connected with the primary network as the crawl continued.

Potential fraud or law enforcement?

Subdomain enumeration
Adversarial website which uses subdomains to attack the frontier manager, initially thought to be a bug. After discovering this website, the frontier manager was changed to no longer consider a subdomain to be the “primary” unique identifier. The website contains a privacy manifesto not shown on this document.
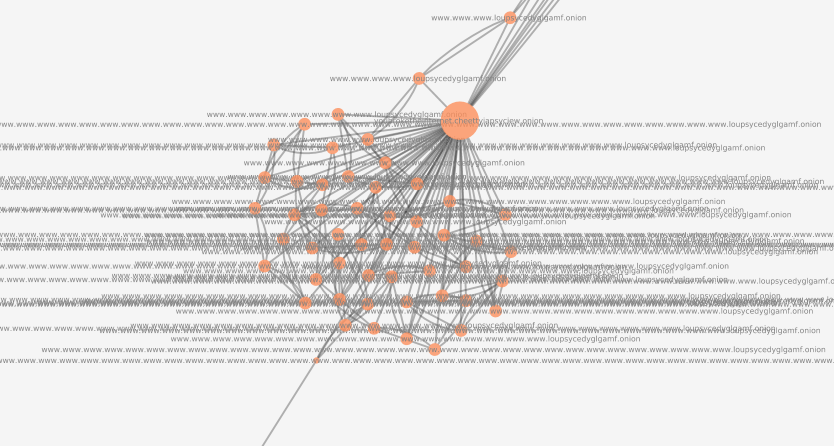
Full visualization